
Printed timetable books were meant to be read by humans, last for no more than a year and then be discarded.
In this section, we describe some of the challenges encountered when digitising timetable books and the technologies that have made it possible. As a group of volunteers, we are still learning and by sharing this inside information we welcome any insights and improvements you can suggest.
Book production methods have developed since the first Bradshaw's in 1839. The diversity of materials, bindings, and layouts we encounter have required Timetable World volunteers to adopt a variety of techniques for digitising.
Paper quality is generally poor. Books with acidic paper typically show some yellowing at the edges, which extends across the sheets in the oldest books, and it can sometimes become flaky too. Cheap overly absorbent paper caused print to bleed and be hard to read, and paper thinness can be an issue, where strong lighting causes the reverse side to show through. Colour print in newer timetables required shinier paper, but to scan it requires a different lighting setup for it to work well. Some of our earlier books show reflection on the shiny covers because the settings were not adjusted from the matt paper of the book.

Bindings “Perfect” binding uses a hot-melt adhesive and is quite common for timetables because it is cheap and quick. Books do not, however, open flat without breaking the adhesive. It can be a challenge to uncurl the pages sufficiently to scan into the binding. We have also observed that shiny paper can become badly wrinkled when perfect bound because it has less “give”. The Swiss timetables, for instance, are manufactured to a high standard but show several of these effects by having tiny margins, perfect binding and shiny paper.
Stapling of books was common up to the 1950s as a cheaper alternative to stitching for thicker books, with the staples often hidden. Such books are problmetic for non-destructive scanning because the books open irregularly. Removing heavy-duty staples for destructive scanning usually achieves better results.
Print mis-alignment of pages occasionally causes important information to be lost to the guillotine or into the bindings.
Page numbering is rarely straightforward. Many timetables have multiple sections, and may restart the numbering sequences – at 1, at another arbitrary point, by switching to/from Roman numerals and so on. Bradshaw’s randomly insert letters into the sequence 101, 101a, 101b, 102 etc.
We offer collectors the opportunity for their timetables to be digitised non-destructively or destructively, depending on the rarity value. Occasionally, a book or its bindings can fall to dust and give us no choice but, so far, that has only happened once.
Large-format scanning, mainly for maps, is also available.
Early days
When Timetable World began in 2009, a ‘book’ scanner was a flatbed scanner shaped to get deep into the binding. It still required the book to be manoeuvred between each scan and was therefore slow to use.

To address the productivity issue, a home-made book-shaped cradle was adopted for Timetable World, with two inexpensive 8-megapixel cameras taking shots of the opposing pages. It worked well because the pages faced the cameras and just needed turning, and the cameras could zoom in and out to avoid too much border being captured. Post-processing was time-consuming and complicated, however.
Non-Destructive Scanning
More recently, overhead book scanners have become a consumer product, and they are more affordable than the professional versions previously shipping. Timetable World purchased the Czur ET16 and it has made a major contribution to speeding up the initial scanning work. Another volunteer purchased the later ET18 but they seem little different.

The overhead scanner works as follows:
There are many additional software features to assist post-processing, but these are the main steps at scan-time. The scanner will handle flat items, such as maps, up to A3, but is not sufficiently high-resolution for photographs. It is worth noting that the original scanning method captured at higher precision, but the lower Czur resolution seems to be sufficient.
The two volunteers with scanners have adopted different ways of working. The preferred approach of one is to scan quickly and fix the problems later, comfortably reaching 600 pages per hour. The scanner gets overloaded if you work too fast. Google Drive is used to transfer large files.
Destructive Scanning
Taking a book apart for scanning is now an option offered by Timetable World. It bypasses the problems of bindings and page curvature, and is certainly much quicker to scan. The resulting sheets cannot normally be re-assembled into a book, which is what makes it a "destructive" approach, and is not suitable for rarer books.

The sheet scanner produces high-quality scans that require little-or-no tidying afterward. It detects mis-feeds, straightens images, and numbers the pages reliably.
The quality achieved makes sheet scanning a cost- and time-effective way of digitising.
Map Scanning
Timetable World does not yet have access to a specialised scanner for large-format (>A3) sheets. However, we have been able to achieve satisfactory results by building composite images from multiple scans. Microsoft previously offered a free tool called ICE - Image Composite Editor that automatically builds the image from separate overlapping scans. For reasons unknown, the Microsoft links have been removed so we cannot share them with you.
The main tasks to tidy the scans are:
The grid layouts require some judgement and care to lay them out logically. The general rule is one book equals one grid, but the technology allows for many books to go onto a single grid. The latter can be an appropriate way of grouping magazine editions, leaflets or multi-part timetables. Example: The OBB (Austria) timetable is published as two books
An important change in our approach was to reduce the essential indexing required for publication. That is not to say we index less – instead, much of the indexing work can be left until after publication and undertaken remotely by volunteers.
Three levels of indexing can be applied –
OCR should be helpful for indexing but we struggle to get satisfactory results. It would add great value to capture the station indexes effectively. The problems seem to be:
There is scope for a PhD-level AI project for someone to solve this. It would be more valuable than for just hobby purposes.
Speedy access to huge timetables can only be achieved by serving images as needed, never downloading the whole book. Back in 2009 when the approach was brand new, we adopted the “tile pyramid” to achieve this, and it is still the principle used today – by Timetable World, Google Maps and numerous other providers of large imagery.
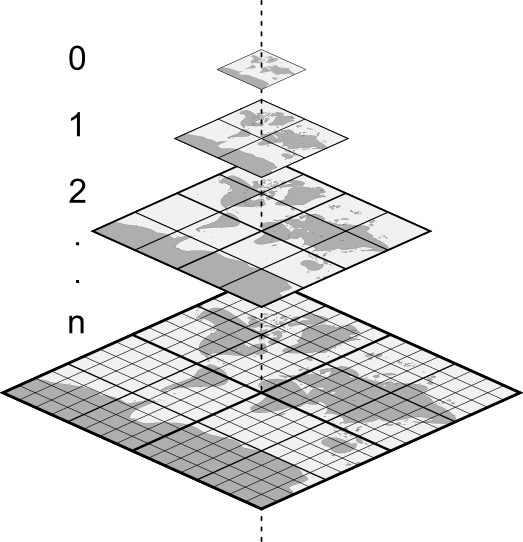
The images we have scanned are divided into 256×256 pixel tiles. Each group of four tiles is then shrunk by 50% to make a fifth summary tile. The process is repeated until there is just one tile at the top of a pyramid encompassing a whole book. As you browse the viewer, only the tiles needed are downloaded. Mobile devices can therefore be used; there is no need to download a huge PDF file first.
The Timetable World books are published as a public web service. Anyone technically minded can include them in other websites; all that is needed is a suitable viewer. It’s free but please credit us. Timetable World uses Leaflet, a leading open-source Javascript solution. NB: The legacy part of the website from 2009 uses PanoJS rather than Leaflet.
Please contact us for advice and documentation for embedding our web services in your website.


The main change between 2009 and 2020 technology is that tiles are no longer held as real files. Instead, the tiles are stored in a PostGreSQL database as binary large objects (BLOBs) and are converted to image files on demand.
Databases are better at managing large volumes of data – including binary image data – than the operating system, and the former method cannot scale up. The web server has a daemon called TileStache running; when requests for tiles come in, TileStache queries the database and converts the BLOB back to an image file – all within milliseconds.
The MBTILES database model was sponsored by MapBox for serving map images. It is a design dating back several years and is probably now some way off the pace. Timetable World has extended the model to cope with multiple tile pyramids and it meets our needs for now.
The volunteer-prepared index data is stored in the same database. It is used to lay out the grid, manage the labels and bookmarks, and to serve the tiles.
The final piece is Python, the programming language. Timetable World uses Python to convert the scans into tiles and upload them to the database, ready to be served.
